TVM Schedule for Matrix Transpose
Tensor computations are heavily influenced by their underlying hardware(GPUs,CPUs,Microcontrollers etc..) However hardware must be carefully programmed, taking advantage of several low level properties such as memory hierarchy and cache sizes. Thus for each computation we would need N(number of hardware classes) * M(Hardware properties) versions of optimized code. TVM provides a solution, by allowing us to specify a template schedule for a computation which can automatically be tuned for Hardware specific properties.
In this example we study the classical problem of matrix transpose where the input-output matrices are stored in a row major format. In general, sequential memory (read|write) access is preferred as they have higher locality and make a better use of caching mechanisms. Matrix transpose however has an interesting property that the input and output have an orthoganal access pattern. A simple two loop solution has to either choose between row-wise(read)-column-wise(write) or column-wise(read)-row-wise(write). Thus we incur poor locality due to column-wise operations even in the presence of highly local row-wise operations.
[Diagram Memory access and code]
tranpose(A(n,n),B(n,n))
for i in (0,n):
for j in (0,n):
B[j][i] = A[i][j]
Mapping this problem on to the GPU we can map (i to blockIdx) and (j to threadIdx) in the following tvm schedule.
A = te.placeholder((m, n), name="A")
B = te.compute((m, n), lambda i, j: A[j, i], name="B")
s = te.create_schedule([B.op])
s[B].bind(B.op.axis[0],te.thread_axis("blockIdx.x"))
s[B].bind(B.op.axis[1],te.thread_axis("threadIdx.x"))
naive = tvm.build(s,[A,B],target="cuda",name="transpose")
return naive
Running the generated kernel with nvprof shows that the computation accounts for 27% of runtime. While we cant decrease the memcpy cost, we can reduce the cost of computation using shared memory.
| Type | Time(%) | Time | Calls | Avg | Min | Max | Name |
|---|---|---|---|---|---|---|---|
| GPU activities: | 73.20% | 1.4017ms | 2 | 700.85us | 676.47us | 725.24us | [CUDA memcpy HtoD] |
| 26.80% | 513.22us | 10 | 51.321us | 49.533us | 52.509us | transpose_kernel0 |
However we cant naively apply our cache as the acess pattern is too scattered. To improve locality, we need to split our iteration to focus on small chunks. We start our manipulation of the above schedule by first splitting the 2 loops into 4 loops, such that the inner loops work on a fixed array of size (32,32)
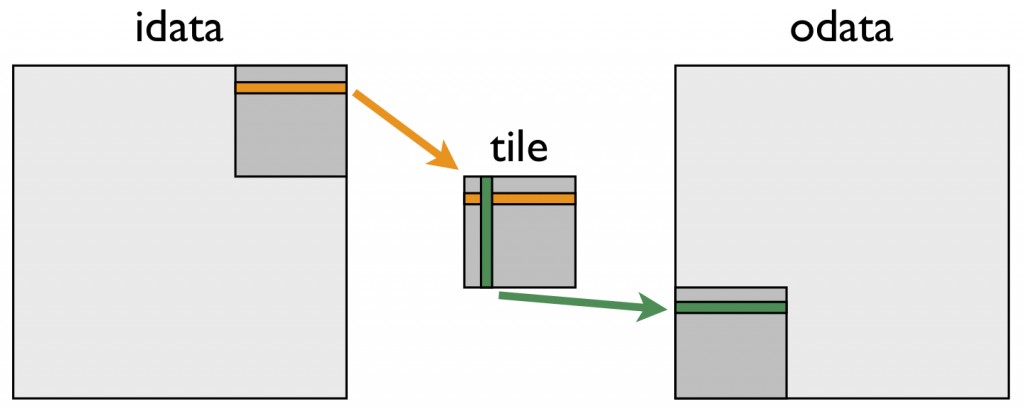
x,y,f1,f2 = s[B].tile(B.op.axis[0],B.op.axis[1],x_factor=32,y_factor=32)
block = s[B].fuse(x,y)
s[B].bind(block,te.thread_axis("blockIdx.x"))
s[B].bind(f2,te.thread_axis("threadIdx.x"))
F = tvm.build(s,[A,B], target = "cuda", name = "tiled_but_not_shared")
| Type | Time(%) | Time | Calls | Avg | Min | Max | Name |
|---|---|---|---|---|---|---|---|
| GPU activities: | 52.87% | 1.5760ms | 10 | 157.60us | 153.85us | 165.17us | tiled_but_not_shared_kernel0 |
| 47.13% | 1.4047ms | 2 | 702.37us | 677.62us | 727.12us | [CUDA memcpy HtoD] |
We want to store the A[32][32] matrix we need inside the shared memory using sequential reads and write it to B using sequential writes to global memory and non-sequential reads from shared memory.
In tvm we can cache all the memory accesses being made on a tensor with a simple.
AA = s.cache_read(A,"shared",[B])
There are 2 distinct operations, one reading into shared memory and writing to global memory. These 2 operations have to be positioned, iteration axes defined and bound to kernel indices. The shared memory is first tiled and its column wise writes are bound to threadIdx.x. Similarly writes to global memory are also tiled and their row wise writes are bound to threadIdx.x Now these two operations are ordered with respect to each other by with compute_at. The full code is shown below.
B = te.compute((m,n), lambda i,j: A[j,i], name = "B")
s = te.create_schedule([B.op])
AA = s.cache_read(A,"shared",[B])
x,y,f1,f2 = s[AA].tile(AA.op.axis[0],AA.op.axis[1],x_factor=32,y_factor=32)
block = s[AA].fuse(x,y)
s[AA].bind(block,te.thread_axis("blockIdx.x"))
s[AA].bind(f1,te.thread_axis("threadIdx.x"))
x,y,f1,f2 = s[B].tile(B.op.axis[0],B.op.axis[1],x_factor=32,y_factor=32)
block = s[B].fuse(x,y)
s[AA].compute_at(s[B],block)
s[B].bind(block,te.thread_axis("blockIdx.x"))
s[B].bind(f2,te.thread_axis("threadIdx.x"))
Profiling our code again we see that now to kernel computation cost has come under 10%
| Type | Time(%) | Time | Calls | Avg | Min | Max | Name |
|---|---|---|---|---|---|---|---|
| GPU activities: | 90.77% | 1.3978ms | 2 | 698.90us | 672.82us | 724.98us | [CUDA memcpy HtoD] |
| 9.23% | 142.14us | 10 | 14.213us | 13.951us | 15.999us | tiled_shared_kernel0 |
Til next time,
Sandeep Polisetty
at 00:00
